I’m a huge fan of comedian Brian Regan. I love that his humor is clean, and he is a genuinely funny guy. One of his older routines has a bit on watching fishing on TV. He asks his audience, “Do you ever watch fishing on TV for like 15 minutes and then just go: ‘Boy, I’d better get a life. I’m watching fishing. I’m not even fishing, I’m watching fishing. I’m too lazy to fish… I’m taping fishing, to watch again later!'” While it does seem silly to watch fishing instead of going out to do it, I really enjoy being able to watch fishing during the winter months. When you can’t be out in a boat, it’s nice to be able to remember the warmth of the sun and the kiss of fresh lake air on your skin, not to mention the thrill of a strong fish tugging from the end of your line. In addition to the sweet memories these shows can evoke, they can also teach new tactics that can be used to improve your techniques. It’s important to pay attention to what the professionals are doing in order to improve yourself.
As a DBA, we should also be paying attention to news in the industry. A few weeks ago we were met with news of a few security flaws that have the potential to cause big problems. These flaws, named Meltdown and Spectre, exploit a vulnerability in the processor, so they affect almost all computers. As a DBA you have at least two places to address this: in the server OS software and in SQL Server. Here is a Microsoft’s guidance for protecting SQL Server from these vulnerabilities. It’s important to note that Microsoft is advising us to evaluate the performance impact of these patches. They do fix the vulnerability, but they have the potential to degrade performance, at least a bit. Those that use certain extensibility mechanisms with SQL Server, such as linked servers or CLR, are most impacted by this issue. On the OS side, unfortunately as of the time of writing this blog we still don’t have OS patches for two version of Windows Server – 2008 and 2012. If you are using either of these versions, check back on this page often to find out when these patches become available, and get them applied.
Moving UNDO and TEMP files in Oracle
This summer I had the pleasure of reading a couple of really good muskie fishing books. The first was Musky Strategy by row-trolling legend Tom Gelb. There were a number of cool things in this book, but the main thing that struck me was how scientific Tom’s approach to muskie fishing is. He went so far as to test the depth his lures ran while trolling by rowing parallel to a shoreline over and over from deep to shallow to see when the lure started contacting the bottom. The book was a fun read, and showed how can you succeed without all the modern electronic tools as long as you’re willing to put in the time. The second was Time on the Water by Bill Gardner. This book was a story instead of a nonfictional book to teach tactics. It tells the story of one man’s quest to catch a big muskie while fishing the entire season for a year in Northern Wisconsin. It was a fun read, and the main takeaway here was just how difficult it is to catch a big muskie, even when fishing for them every day. If you like fishing, check out the books!
Loss of free space on a disk is something that we as DBAs are always dealing with. Perhaps we are able to ask our SAN admin to give us more space, but in many cases we are not. In those cases, moving database files from one logical drive to another can answer this challenge. Note that care should be taken when considering moving database files. Drives can be different speeds, and their may be a reason a database file is on one drive an not another.
I recently needed to move a couple Oracle system tablespace files (UNDO and TEMP) from the C: drive (where they never should have been put in the first place) to a different drive.
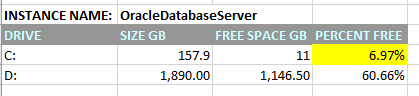
The method for doing this is relatively simple. Create a second tablespace for each on the “other” drive, make it the default tablespace, and drop the original tablespace.
CREATE TEMPORARY TABLESPACE temp2 TEMPFILE 'D:\APP\ORACLE\ORADATA\LEGENDOPRD\TEMP03.DBF' size 30G AUTOEXTEND ON NEXT 1G MAXSIZE unlimited;
ALTER DATABASE DEFAULT TEMPORARY TABLESPACE temp2;
DROP TABLESPACE TEMP INCLUDING CONTENTS AND DATAFILES;
CREATE UNDO TABLESPACE undotbs2 datafile 'D:\APP\ORACLE\ORADATA\LEGENDOPRD\UNDO02.DBF' size 20G;
ALTER SYSTEM SET undo_tablespace=undotbs2;
DROP tablespace UNDOTBS1 INCLUDING CONTENTS;
I found after doing this I still needed to delete the old files from the OS folder, and I couldn’t do that until the Oracle database service had been recycled, but after that my drive space was much healthier.
Custom Roles in SSRS
Our world continues to drift into virtual reality. I don’t, of course, mean actual virtual reality, but I do mean we are growing further and further away from the great outdoors and closer and closer to spending all our team immersed in technology. A Nielsen Company audience report from 2016 indicated adults in the US devoted about 10 hours and 39 minutes each day to consuming media (tablets, smartphones, computers, TVs, etc.). A BBC news article reports that kids aged 5 – 16 spend an average of 6.5 hours each day in front of a screen, compared to just three hours back in 1995. This trend is scary for a number of reasons, but it is clear that many people, especially kids, are losing out on experiencing the great outdoors. There is nothing in the virtual world that can compare to feeling a big fish tugging on the end of your line, or sitting in a tree stand as a deer stealthily approaches, or even just taking a walk around a lake and enjoying the fresh air and beautiful view. It’s up to us adults to teach our children the joy of outdoor sports.
Somehow, up until this point in my DBA career I’ve never had to mess with custom SSRS permissions. SSRS installs with five permissions roles by default.
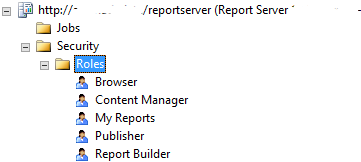
As such, I was completely unaware that you can create your own custom roles. You can’t do this from Report Manager, as far as I could find in my SSRS 2008 R2 version. I had to log into the Report Server with SSMS. As a side note, logging in with Windows Authentication using localhost as the server didn’t work. I actually had to put in http://servername/reportserver to use Windows Authentication, even when logging in from on the server.
Once I had successfully logged in, I was able to add a new role.
I wanted to create a role that would allow a user to manage subscriptions for others. The only built in role that has that permission is Content Manager, but that role also has several other permissions that I didn’t want to confer on my target user. Remember a user can have multiple roles, so there is not reason not to get as granular as necessary. Below are the Tasks available for assigning to the custom roles:
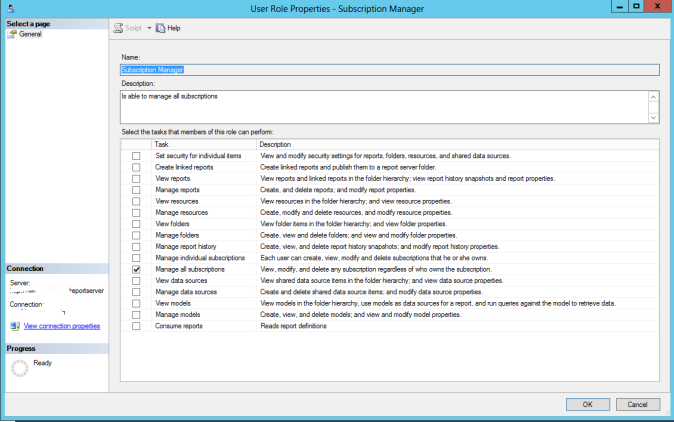
Similarly, System Roles can also be customized. By default there is only System Administrator and System User. Here are the options for creating a new System Role.
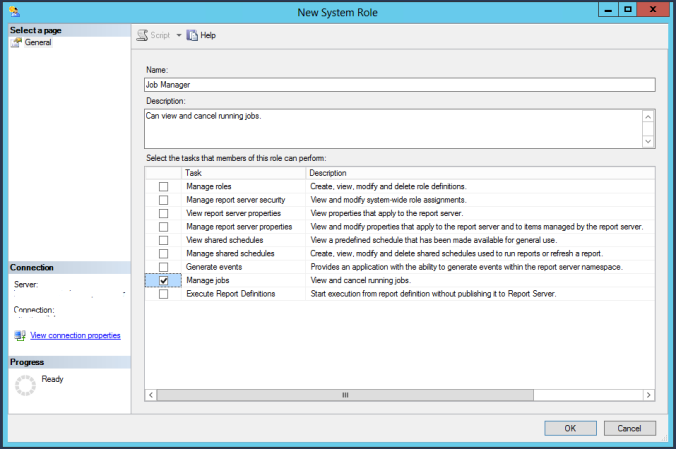
Using custom roles can make your job of managing the permissions on Reporting Services easier and more precise.
Vendor Woes
The season has gotten late. I don’t have any recent fishing stories to share; I’ve spent most of this fall hunting instead. I’ll have to take the boat back down to the lake one more time to winterize the motor, but then it will be moved into the garage to await the thaw in spring. It’s always sad when the fishing season ends, but this year I’ve had so much fun bow hunting that I haven’t even noticed.

Two Does Within Range
The lesson from this blog post will not be technical. Rather, it will be about applying good expectations on your vendors. This is probably most important to the DBA folks as they consider using cloud infrastructure.
The company I currently work for uses a third party cloud platform for our website hosting. We have no retail stores, and over 90% of our business comes from internet sales. Additionally, we are very seasonal, doing well over half our sales in the final two months of the calendar year. We spend the other ten months preparing for this busy sales period. Any technical issues during November or December can have catastrophic consequences to our bottom line. As you can expect, it is extremely important that our website remain functional from late fall through winter.
I’m sure you can see where I’m going with this. Our website hosting provider, a very well known company, has been abysmal so far this fall. We’ve had several unexpected outages, several scheduled outages, and very little explanation for it. We’ve had periods where our website has been unavailable for over 12 hours at a time. Our management has grown increasingly frusterated with this third party provider and, to a lesser degree, the IT department as well. In examining our contract, we were shocked to see no promise of uptime. I’m not sure how this was missed when we signed up for this service.
We will most likely be seeking to end our relationship with this company before our contract ends. Unfortunately, there is no time to procure another solution before the end of the year. We’re just going to have to live with the results. We may also be sued for breach of contract for seeking an early release, but with all the problems we’ve had I’m not sure that will happen.
Either way, the lesson here is to do a thorough investigation of any company you will be depending on. If you are looking at cloud services, find out ahead of time the expectations for uptime and maintenance outages. I would also be ready for imposing financial penalties on the vendor if those expectations are not met.
Inserting into SQL Server from Powershell using parameters
Sometimes fishing, especially muskie fishing, just doesn’t go your way. I recently took a trip to Northern Wisconsin to do some hunting and fishing. I spent five days beating the water to a froth with my lures, but ended up seeing only a single follow. When you’re faced with that level of failure, it’s common to search everywhere for reasons. Was the weather too warm? Was I fishing in the wrong spots? Was I using the wrong types of lures? Was I fishing too fast? Was I fishing too slow? Am I just a bad fisherman? Muskie fishing is all about developing patterns, but it’s awfully tough to find a pattern when you aren’t seeing any fish. I’m going to chalk my failure on this trip up to poor weather. Although it’s now fall, the temperatures have been setting record highs. I’m thinking the fish are just waiting for the water to start cooling so they can binge feed and put on the winter fat. But who knows? Maybe I am just a bad fisherman.

Bad weather chased me off the water after just two hours of fishing on one day.
I recently constructed an IT dashboard. This dashboard, built in SSRS, compiled data from several sources into a SQL Server database where it could be quickly grabbed by SSRS. The part of this task that was new for me was grabbing performance counters from an array of remote servers and inserting them into the SQL Server table. I was able to make use of a Powershell SYSTEM.DATA.SQLCLIENT.SQQLCOMMAND for this. Below I’ll show how I did it.
First I need a table to hold the data. For this specific set of metrics I’m going to be collecting memory used by the servers.
CREATE TABLE [dbo].[IT_DB_Memory](
[ServerName] [VARCHAR](255) NOT NULL,
[MemoryUsed_GB] [DECIMAL](5, 2) NOT NULL,
[CaptureDateTime] [DATETIME2](7) NOT NULL,
CONSTRAINT [PK_IT_DB_Memory] PRIMARY KEY CLUSTERED
(
[ServerName] ASC,
[CaptureDateTime] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]Now that I have a table, I will build the powershell script. This is going to run over multiple servers. First I need to set up an array with the list of servers I plan to survey.
$serverarray = @(('Muskie'),('NorthernPike'),('Walleye'))
That’s right, I name my servers after fish. Next I’ll create a connection to SQL Server.
$sqlConn = New-OBJECT SYSTEM.DATA.SqlClient.SQLConnection $sqlConn.ConnectionString = "Server=SmallmouthBass;Database=DBAReporting;Integrated Security=True;" $sqlConn.OPEN()
Now I create the command that will be run. Note the SQL Server parameters as distinguished by @ in the front of it.
$sqlCmnd = New-OBJECT SYSTEM.DATA.SqlClient.SqlCommand $sqlCmnd.CONNECTION = $SqlConn $sqlCmnd.CommandText = " SET NOCOUNT ON; INSERT INTO DBAReporting.dbo.IT_DB_Memory ( ServerName , MemoryUsed_GB , CaptureDateTime ) VALUES ( @ServerName , @MemoryUsed / 1073741824 , GETDATE());"
Next I’ll actually create those parameters in the Powershell SQL command.
$sqlCmnd.Parameters.ADD((New-OBJECT DATA.SQLClient.SQLParameter("@ServerName",[Data.SQLDBType]::VarChar, 255))) | OUT-NULL $sqlCmnd.Parameters.ADD((New-OBJECT DATA.SQLClient.SQLParameter("@MemoryUsed",[Data.SQLDBType]::DECIMAL, 5,2))) | OUT-NULL
This next step is what does the actual work. I’ll loop through the array and use the GET-COUNTER command to get the Memory Used. The way I have it set up will give sample the memory five times, once per second, and then return the average of those five samples.
foreach ($server in $serverarray) { $sqlCmnd.Parameters[0].Value = $server $Memory = GET-COUNTER -COUNTER "\Memory\Committed Bytes" -SampleInterval 1 -MaxSamples 5 -ComputerName $server | select -ExpandProperty countersamples | select -ExpandProperty cookedvalue | Measure-Object -Average $sqlCmnd.Parameters[1].Value = $Memory.Average $sqlCmnd.ExecuteScalar() }
The last step in Powershell is simply to close the database connection.
$SqlConn.Close()
Now I can set this to run on a regular basis using Windows Task Scheduler, and I’ll have a history of how my application servers are using memory throughout the day.
Tally Tables
Occasionally I like to take a break from Muskie fishing and spend time catching some easier species. This is especially true when I’m taking friends out fishing. Not many people like to cast for hours with only a few follows to show for it. Last month I took my brother Steve out onto a smaller lake about five minutes from my house. This lake is overrun with invasive weeds, and I tend to think of it as a garbage lake. However, we had a great time catching fish. My brother caught several bass and a bonus walleye, while I managed this fat 30″ pike. The pike took a good 5 minutes to get in the boat since I was using fairly light tackle and we had no net.

SQL is a set based language. It is built with the idea that the engine will handle any looping in the background, without the author needing to specify the best way to loop. There are a few rare exceptions, but if you are creating a loop in SQL, you are usually doing something wrong or much less efficiently. One great way to get around loops is to create a Tally Table. Originally defined by SQL Server legend Jeff Moden in 2008, the Tally Table is simply a table with a single column of very well indexed sequential numbers.
If you’re a programmer or developer, you’re probably going to think of something like this to build a Tally Table:
--Create the Tally Table
CREATE TABLE #Tally
(
N INT
, CONSTRAINT PK_Tally_N
PRIMARY KEY CLUSTERED (N)
);
--Set up a increment counter
DECLARE @TallyCounter INT;
SET @TallyCounter = 1;
--Fill the Tally Table with a Loop
WHILE @TallyCounter <= 11000
BEGIN
INSERT INTO #Tally
(
N
)
VALUES (@TallyCounter);
SET @TallyCounter = @TallyCounter + 1;
END;Running on my server, this code took an avergage of 432 milisecond while requiring 22,426 reads and 407 CPU. A more efficient way to generate the table will be like this:
--Create and populate table
SELECT TOP 11000
IDENTITY(INT, 1, 1) AS N
INTO #Tally
FROM MASTER.sys.syscolumns sc1
, MASTER.sys.syscolumns sc2;
--Add Primary Key Clustered
ALTER TABLE #Tally
ADD CONSTRAINT PK_Tally_N
PRIMARY KEY CLUSTERED (N) WITH FILLFACTOR = 100;This took me only 73 miliseconds to run, and required only 885 reads and 78 CPU.
In Oracle this is even easier to create:
CREATE TABLE tempTally AS
SELECT LEVEL AS N
FROM DUAL
CONNECT BY LEVEL <= 11000
ORDER BY LEVEL;
So now we’ve got a table full of sequential numbers from 1 to 11,000. What can we use this for?
From a programmer or developer perspective, loops are often used with strings. Let’s say we want to step through and display each character in a string. With a loop, you’d do something like this:
DECLARE @StepThroughMe VARCHAR(100), @i INT;
SELECT @StepThroughMe = 'Looping through this string is a waste of time.', @i = 1;
WHILE @i <= LEN(@StepThroughMe)
BEGIN
SELECT @i, SUBSTRING(@StepThroughMe, @i, 1);
SELECT @i = @i+1
END;Using a Tally table, you can do it in a way that is simpler to write and runs in less than a tenth of the time:
DECLARE @TallyThroughMe VARCHAR(100);
SELECT @TallyThroughMe = 'Using a Tally Table is an efficient use of time.'
SELECT t.N, SUBSTRING(@TallyThroughMe, t.N, 1)
FROM #Tally AS t
WHERE t.N <= LEN(@TallyThroughMe);One other way I used this was to create my Date table in my date warehouse.
WITH cte
AS (SELECT DATEADD(DAY, N - 1, '2000-01-01') AS Date
FROM #Tally
)
SELECT YEAR(cte.Date) * 10000 + MONTH(cte.Date) * 100 + DAY(cte.Date) AS DateKey
, cte.Date
, YEAR(cte.Date) AS YEAR
, DATEPART(QUARTER, cte.Date) AS Quarter
, MONTH(cte.Date) AS MONTH
, RIGHT('0' + CAST(MONTH(cte.Date) AS VARCHAR(2)), 2) + '. ' + DATENAME(MONTH, cte.Date) AS MonthName
, DATEPART(ww, cte.Date) + 1 - DATEPART(ww, CAST(DATEPART(mm, cte.Date) AS VARCHAR) + '/1/' + CAST(DATEPART(yy, cte.Date) AS VARCHAR)) AS WeekOfMonth
, DATEPART(wk, cte.Date) AS WeekOfYear
, DATEPART(dw, cte.Date) AS DayOfWeek
, RIGHT('0' + DATEPART(dw, cte.Date), 2) + '. ' + DATENAME(dw, cte.Date) AS DayOfWeekName
, DAY(cte.Date) AS DayOfMonth
, DATEPART(DAYOFYEAR, cte.Date) AS DayOfYear
, CASE
WHEN DATEPART(QUARTER, cte.Date) IN ( 1, 2 ) THEN
'Spring'
ELSE
'Fall'
END AS RetailSeason
FROM cte;This worked for loading my permanent table, but you could also use it to load a temp table or table variable that could be joined to a data set to get a full range of dates even when your data set is missing data on some of the dates.
Tally tables can be used to improve performance in a number of different scenarios. Next time you’re not sure whether you may need a loop, stop and consider whether your situation may benefit from a Tally Table.
SQL Agent Properties
It’s been a rather windy summer thus far, making it less fun to be out on the water. I don’t know many guys who enjoyed being blasted by the wind while bobbing up and down on the waves for hours on end. I went out on Pewaukee Lake a few weeks ago with a buddy from work. We had picked the day in advance since it was supposed to be dry and calm. We got the dry, but not the calm. We had a stiff wind blowing out of the west that drove us back into the western half of the lake after trying to fish the narrows in the middle.
I spent the day focusing my fishing efforts on making the bait look real. I tried hard to avoid retrieving the lure in a rhythmic fashion. I was paid off with a nice upper 30s muskie:

My fishing buddy hooked one a short time later, but couldn’t keep it pinned and we lost it.
Recently, I blogged about migrating the SQL Server installation onto a different drive. I did find one problem after this move that I had to address. I ran into a problem with the SQL Agent and I wasn’t able to diagnose the issue. If I remember correctly it was actually an SSRS subscription that failed, and I needed details to find out why. I found that the SQL Agent has properties, and the error log was still pointing back at the previous location on the C: drive, which no longer existed. There is a stored procedure you can execute to see those properties, in addition to looking at them in the SSMS UI:
EXEC msdb..sp_get_sqlagent_properties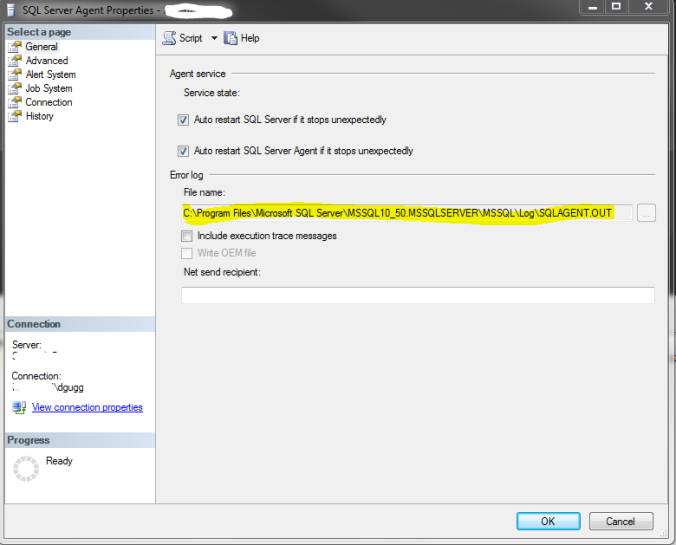
Lastly, just update the value with the corresponding SET stored procedure and restart the SQL Agent:
EXEC msdb..sp_set_sqlagent_properties
@errorlog_file = N'D:\SQLSERVERINSTALL\SQLAGENTERRORLOG.log'
Now your SQL Agent properties have been update.
Addressing login trigger failures in SQL Server
As I get older I have come to enjoy watching others fish, especially my children. The thrill of catching a big fish is magnified by seeing the smile on someone else’s face when he/she is the one bringing it in. Below is a nice sized largemouth bass my son caught on a recent fishing trip.

In my previous post I showed how to create a login trigger to log sysadmin access to a SQL Server instance. Almost immediately I received a comment describing how the failure of the trigger could almost completely prevent anyone from logging into the instance. This is a major problem!
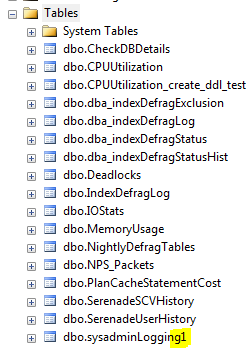
The reason this occurs makes sense if you think about it. While attempting to login, the user executes some code in a trigger. If that code is invalid, the trigger will fail and abort. When that happens, the login aborts as well. What could cause the trigger to fail? Well, if the table (or other objects) you are accessing within the trigger is inaccessible to the user, or if it doesn’t even exist, the trigger will fail.
I tested this by using my working trigger, which logged sysadmin logins to a table called dbo.sysadminLogging. Next I renamed the table to dbo.sysadminLogging1.
Next I tried to login in a new window in SSMS:
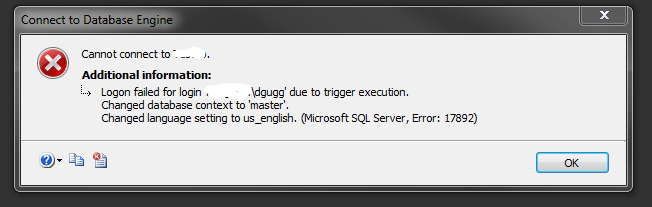
First, let’s talk about how to get back into a server that has this issue. We need to log into the SQL using SQLCMD with a dedicated administrator connection, then disable the trigger:

After doing this everyone should now be able to log back into SQL Server as normal.
Now to prevent this type of event from happening, I suggest a small edit to my original trigger. This edit will make sure the referenced objects are valid. If not, the trigger does nothing. It may also be a good idea to send an email to the DBA so they can investigate, and I’ve noted that in the comments.
CREATE TRIGGER [servertrigger_CheckForSysAdminLogin] ON ALL SERVER
FOR LOGON
AS
BEGIN
IF OBJECT_ID('DBMaint.dbo.sysadminLogging') IS NULL
BEGIN
--Possibly send an email to the DBA, indicating the trigger is not working as expected
GOTO Abort;--Do nothing
END
IF IS_SRVROLEMEMBER('sysadmin') = 1
BEGIN
INSERT INTO DBMaint.dbo.sysadminLogging
( [Login] , LoginDate )
VALUES ( ORIGINAL_LOGIN() , GETDATE() );
END;
Abort:
END;
GOThis newer version of the trigger should cut down on the chances that this functionality will come back to bite you. Special thanks to james youkhanis for pointing this out.
Logging sysadmin logins in SQL Server
Our yearly cabin opening “men’s weekend” was last weekend. The fishing was a bit below average, but we still had a great time. I brought my six year old son up, and two of my six year old nephews were brought up by their dad’s as well. The first day of fishing we went over to the rainbow flowage, which was a bit of a bust. We ended up hooking five or six northern pike, but only landed one because they kept biting off the line. The boys in the other boat caught some bluegill and bass, but overall the fishing wasn’t as hot as in years past. This was probably due to all the rain they got up there. There were places where the rivers were over the road. Below is the one pike we managed to land.

Security these days is as important as ever. SQL Server provides lots of ways to improve security of your data and environment. One small way I like to keep an eye on my system is to log sysadmin logins to the server. Sysadmin is able to do anything in SQL Server, and by reviewing my log from time to time I can be sure that no one is using this type of login to compromise the system.
The first thing to do is to create a table to hold the log data:
USE [DBA_DB]
GO
CREATE TABLE [dbo].[sysadminLogging](
[SAL_id] [INT] IDENTITY(1,1) NOT NULL,
[Login] [VARCHAR](255) NOT NULL,
[LoginDate] [DATETIME2](7) NOT NULL,
CONSTRAINT [PK_sysadminLogging] PRIMARY KEY NONCLUSTERED
(
[SAL_id] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF, IGNORE_DUP_KEY = OFF, ALLOW_ROW_LOCKS = ON, ALLOW_PAGE_LOCKS = ON) ON [PRIMARY]
) ON [PRIMARY]
GOAll that is left is to create a server level login trigger to record any sysadmin logins to that table:
CREATE TRIGGER [servertrigger_CheckForSysAdminLogin] ON ALL SERVER
FOR LOGON
AS
BEGIN
IF IS_SRVROLEMEMBER('sysadmin') = 1
BEGIN
INSERT INTO DBA_DB.dbo.sysadminLogging
( [Login] , LoginDate )
VALUES ( ORIGINAL_LOGIN() , GETDATE() );
END;
END;
GOCheck this table regularly to get a good idea of who is logging into your SQL Server with these higher privileges.
EDIT:
james youkhanis points out a problem that can occur in the comments. This problem could make logging in quite difficult. I have posted a follow-up where I explain the problem, provide a workaround to allow logging in (as james demonstrates below), and provide an updated trigger to minimize the risk of this occurring.
Upgrade Oracle Database from 11g2 to 12c
The fishing opener has come and gone. I was able to get out for the morning on the day of the opener, from about 6 AM to 11:30 AM. I went with my brother-in-law down to Pewaukee Lake, where we tried to find some early season muskies. I ended up with two follow-ups, one that fled as soon as it saw the boat, and another beauty of a fish that was very aggressive. It followed the lure in hot, right on its tail. It was a bigger fish (somewhere between 40 and 45 inches by my estimation), so instead of doing a figure 8 I went with a big continuous circle next to the boat. I ended up circling somewhere around 10 times with the fish following closely. Each time I swung the lure out away from the boat, the fish would cut the turn and make like it was going to t-bone the lure, but stopped just short. Finally, as I swung the lure back toward the boat, the large fish simply nudged it without even opening its mouth. It clearly was wary, and didn’t want to commit without investigating a bit more. After the nudge the fish took off, I’m sure because it felt the different between a real fish and my plastic Shallow Raider. The follow was a great start to the fishing season, but I’m hoping for more catches this year, not just follows. I did get this largemouth bass as a consolation catch:

Last week I completed an upgrade of the Oracle database in our Production environment. We only have a single application running on our Oracle database as compared to numerous applications running against SQL Server, so I’m not nearly as familiar with working in Oracle. To put it bluntly, I was quite nervous to do the upgrade, and practiced several times in our Test environment before proceeding with the Production upgrade. I was nervous for good reason because the upgrade did not go smoothly at all.
In our Test environment, it took me 3 or 4 tries before I was able to successfully complete the upgrade. I found a few major hurdles to clear:
- I needed a new user created. We currently had a domain user running the existing Oracle database service, but the installer complained that the existing user had some flavor of domain admin rights, and it would not let me proceed with that user.
- Our startup parameter file had a parameter called os_authent_prefix, which was set to doman\. When the upgrade ran I kept getting error messages caused by the \. I guess the upgrade assistant was not smart enough to deal with it, so I removed that parameter before the upgrade, then added it back in afterward. This is an important note! If you are doing an upgrade in the Windows environment, you will probably run into this issue.
- I had to set the job_queue_processes parameter to a higher number, 100.
- I dropped a few deprecated startup parameters, remote_os_authent and cursor_space_for_time. I ended up adding the remote_os_authent back in after the upgrade had completed.
- Lastly, Before the upgrade I compile invalid objects with the UTLRP.SQL job and emptied the Oracle recycle bin.
In addition to those issues which were causing the upgrade process to completely bomb, once I fixed them and got the upgrade to complete I had some cleanup, including the PATH and TNS_ADMIN environment variables, which had to point to the new Oracle home folder structure, and the tnsnames.ora and listener.ora files in the new Oracle home needed to be updated. By the last practice attempt I was getting through the upgrade process in around an hour.
Finally, the night arrived for the Production upgrade. The application is only used during business hours, so I started it at 5 PM once the normal users were finished for the day. The first thing I noticed is a difference in Environment Variables between our Production and Test environment. Production has the ORACLE_HOME environment variable set, and Test does not. This somehow caused the first upgrade attempt to completely fail. Not only did it fail, but it somehow erased the OracleDB service from the list of services in Windows. It took me quite a while to get it back and working again so I could make a second attempt at the upgrade. Although I received some error messages, this one did end up completing successfully. The one thing I wasn’t expecting though was the amount of time it took. While the database that was the same size but on inferior hardware took less than an hour to install in the Test environment, in our Production environment it took well over three hours to install.
I had to perform similar cleanup on the Production environment as in Test, but I also ran into one additional hiccup. After the upgrade I found all accounts except for sys were expired and locked. Now, unlocking an account is not a big problem, but there is not good way to unexpire an account. This is a big problem because many of the accounts can be service accounts, where no actual user is signing in. So no prompt for a new password, and no way to unexpire. Fortunately I found a great workaround on a blog post by Simon Krenger. This method involves replacing the existing encrypted password with that same encrypted password. Once I executed the SQL output by his method, all the accounts were unexpired.
The last step was to gather stats on the relevant databases, and the upgrade was complete.
